浏览器输入域名地址回车,会发生什么?一文了解完整过程!
当你在浏览器输入网址(比如 www.baidu.com)并按下回车后,背后发生了一系列复杂但有序的操作。整个过程大概是这样:
1. 浏览器理解你想去哪
- 检查输入:浏览器先看看你输入的是网址(比如 https://www.baidu.com)还是搜索词(比如“怎么修电脑”)。如果是搜索词,它会直接跳转到默认搜索引擎(比如百度、Google)。
- 补全网址:如果你只输入 baidu,浏览器可能会自动补全成 https://www.baidu.com。
2. 查找网站的“门牌号”(DNS解析)
网址就像“名字”,但互联网实际是靠“IP地址”(类似门牌号)来通信的。所以浏览器需要找到 www.baidu.com 对应的IP地址(比如 14.215.177.38)。
查找顺序:
- 浏览器缓存:先看看自己之前有没有记过这个网址的IP。
- 电脑缓存:如果浏览器没记,问操作系统(比如Windows/Mac)有没有存过。
- 路由器/运营商缓存:如果电脑也不知道,就去问路由器或者网络运营商(比如电信、联通)。
- 全球DNS服务器:如果还是找不到,就一层层问“互联网电话簿”(DNS服务器),最终找到正确的IP。

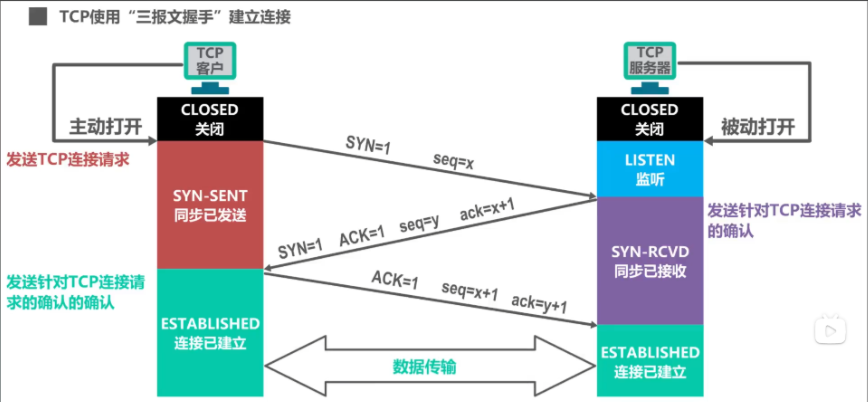
3. 和网站服务器“握手”(建立TCP连接)
拿到IP后,浏览器要和服务器建立连接,分两步:
- TCP三次握手(类似打电话确认对方能接听):浏览器发个“喂,能听到吗?”(SYN)。服务器回“能听到,你那边OK吗?”(SYN-ACK)。浏览器说“好的,那我开始说了”(ACK)。连接建立成功!
- HTTPS加密(如果是安全网站):额外确认网站身份(比如检查证书是不是真的)。双方商量一个“暗号”(加密密钥),后续通信全程加密。
4. 浏览器发送请求:“把首页发给我!”
- 浏览器发送一个HTTP请求,类似:“GET / HTTP/1.1”(意思是:我要根目录下的内容)。可能还附带一些信息:User-Agent(告诉服务器我用的是Chrome还是Safari)。Cookie(比如你之前登录过,带上门票信息)。
5. 服务器处理请求并返回数据
- 服务器收到请求后:可能查数据库、拼装页面(比如你看到的淘宝商品列表)。返回一个“包裹”,里面包含:状态码(比如 200 OK 表示成功,404 表示页面不存在)。网页内容(HTML代码)。其他资源(比如CSS、JS、图片的链接)。
6. 浏览器渲染页面:“把零件组装成网页”
浏览器拿到HTML后,像拼乐高一样逐步构建页面:
- 解析HTML:把代码转换成树状结构(DOM树)。
- 加载CSS/JS:下载样式和脚本,调整页面外观和功能。
- 计算布局:确定每个按钮、文字该放哪儿。
- 绘制页面:把最终效果画出来,显示在屏幕上。
7. 加载其他资源(图片、视频等)
- 如果网页里有图片或视频,浏览器会再发请求去下载它们(可能同时开多个连接)。
- 有些资源可能直接从缓存读取(比如你之前访问过,浏览器懒得重复下载)。
8. 保持或关闭连接
- 现代浏览器默认会保持连接(为了下次访问更快)。
- 如果长时间不用,服务器可能会主动断开。
举个现实中的例子:
你想去朋友家(访问网站):
- 先查通讯录(DNS)找到朋友地址(IP)。
- 打电话(TCP握手)确认他在家。
- 说“我要来找你玩”(HTTP请求)。
- 朋友开门迎接(服务器返回页面)。
- 你进屋后,朋友给你倒水、拿零食(加载图片/CSS/JS)。
- 最后你们一起聊天(页面渲染完成)。
整个过程通常不到1秒,但如果是复杂网站(比如淘宝),可能会更久。浏览器的任务就是尽量让这一切变得更快、更流畅!
标签: 网站建设
本文标题:浏览器输入域名地址回车,会发生什么?一文了解完整过程!
本文链接:https://www.befun.ink/detail/1460.html
声明:本站信息原创或由互联网收集,未用于商业用途,如若侵权,请联系站长删除!
 懒师傅敲代码
懒师傅敲代码

优秀作者 战斗力十足
1.9w
文章
312w+
阅读
635w+
访问量
 相关文章
相关文章